
Client and Context: Manual Consolidation Crippled Forecast Accuracy
A Japanese pharmaceutical company operating at global scale relied on CRO bid-grid documents in a range of non-standard formats to estimate clinical-trial budgets.
The mixed formats forced analysts to stitch data by hand across thousands of documents.
Challenges: Varied Formats, High Volumes, Limited Insight
- Semi-structured PDFs, images, and sheets make automated extraction error prone.
- Thousands of historical and incoming files needed processing without extra headcount.
- Siloed, non-standard data blocked the implementation of centralized storage and reliable cost forecasts.
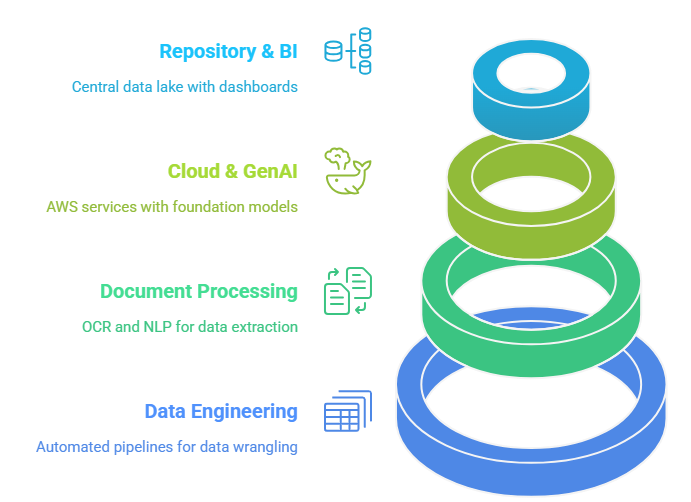
Solution: Dual-Track Extraction with Generative AI
- Baseline pipeline uses conventional OCR/NLP to meet immediate needs.
- GenAI workflow fine-tuned on bid-grid templates pulls and harmonizes key budget fields with higher accuracy.
- Cloud-native on AWS, feeds a governed repository and visualization layer for self-serve analytics.
Benefits: Automation Slashes Cycle Time and Elevates Forecast Quality
- Format-agnostic ingestion cuts manual consolidation and frees analysts.
- Rapid historic upload leads to faster turnaround, which means more data for future projections.
- Improved cost management through harmonized, trustworthy inputs.
- Scalable architecture built for thousands of documents and new data types.
Technology Overview
Impact: AI-Ready Foundation for Continuous Budget Optimization
With GenAI parsing in place, the client can layer predictive models and extend the pipeline across functions, paving the way to a self-service budgeting platform and more accurate, timely financial decisions.
